



克劳德opus 4.7 简介
#新科技应用 时间2026-04-20 10:51:03
IAICA.com.cn---anthropic.com 2026年4月20日
我们最新款的 Claude Opus 4.7 现已全面上市。
Opus 4.7 在高级软件工程方面相比 Opus 4.6 有了显著提升,尤其是在处理最复杂的任务方面。用户反馈,他们现在可以放心地将以前需要密切监督的最棘手的编码工作交给 Opus 4.7 处理。Opus 4.7 能够严谨且一致地处理复杂、耗时的任务,精准地执行指令,并在返回结果之前设计出验证自身输出的方法。
该模型还拥有显著更佳的视觉效果:它能够识别更高分辨率的图像。在完成专业任务时,它更具品味和创造力,能够制作出更高质量的界面、幻灯片和文档。而且,尽管它的功能不如我们最强大的模型 Claude Mythos Preview 全面,但在多项基准测试中,它的表现都优于 Opus 4.6:
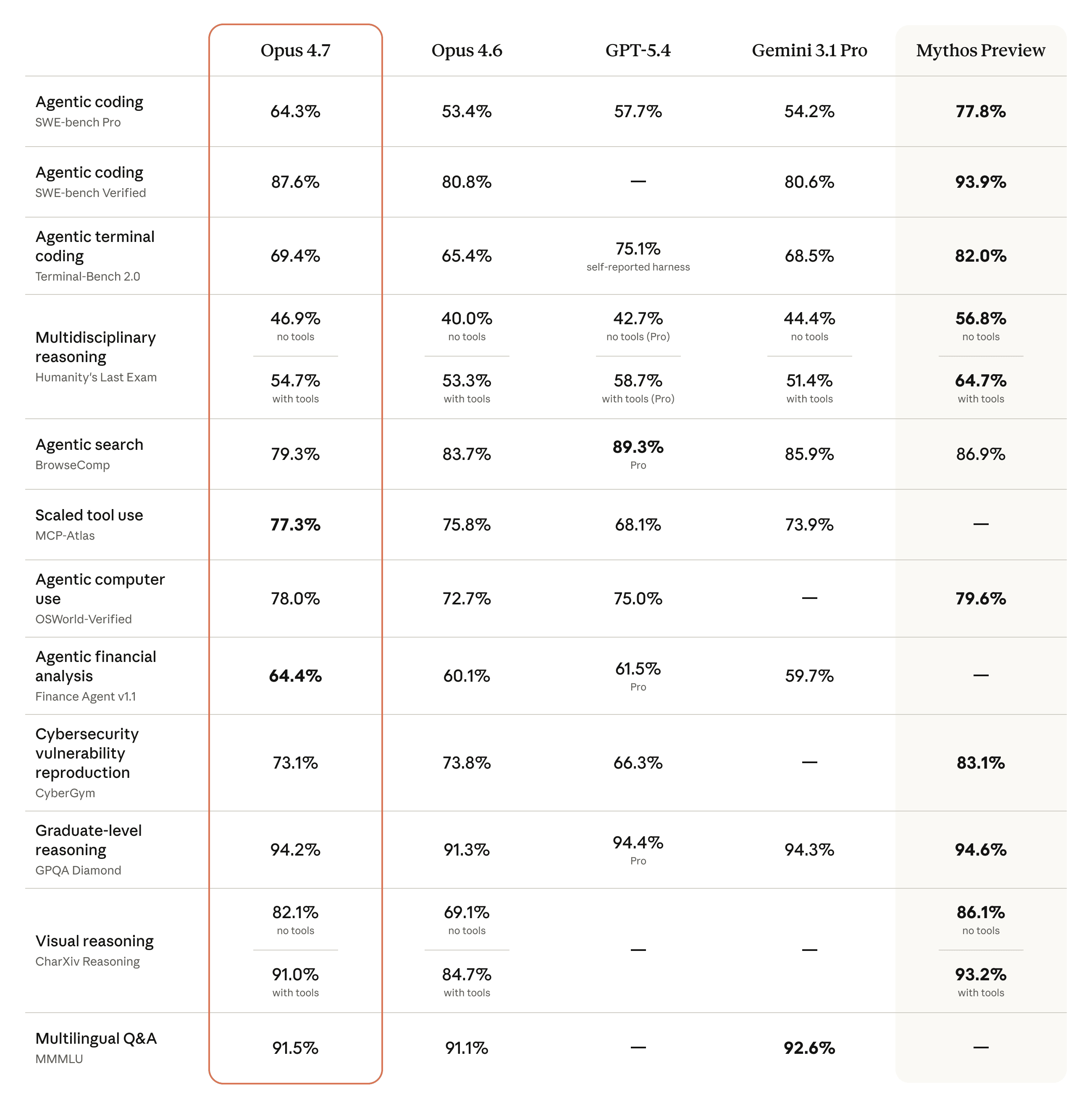
上周我们发布了“玻璃之翼”项目,重点阐述了人工智能模型在网络安全领域的风险与优势。我们声明,我们将限制Claude Mythos Preview的发布范围,并首先在功能较弱的模型上测试新的网络安全防护措施。Opus 4.7是首个此类模型:其网络安全能力不如Mythos Preview(事实上,在训练过程中,我们尝试了多种方法来逐步降低其网络安全能力)。我们发布的Opus 4.7配备了安全防护措施,能够自动检测并阻止表明存在违禁或高风险网络安全用途的请求。我们将从这些安全防护措施的实际部署中获得经验,从而帮助我们最终实现Mythos级模型的广泛发布目标。
受邀将 Opus 4.7 用于合法网络安全目的(例如漏洞研究、渗透测试和红队演练)的安全专业人员加入我们新的网络验证计划。
Opus 4.7 现已在所有 Claude 产品和 API、Amazon Bedrock、Google Cloud 的 Vertex AI 以及 Microsoft Foundry 平台上推出。定价与 Opus 4.6 相同:每百万个输入令牌 5 美元,每百万个输出令牌 25 美元。开发者可claude-opus-4-7通过Claude API使用。
测试 Claude Opus 4.7
Claude Opus 4.7 获得了早期测试用户的强烈反馈:
01/28
以下是我们对 Opus 4.7 进行早期测试的一些亮点和笔记:
指令执行方面,Opus 4.7 的表现有了显著提升。有趣的是,这意味着之前版本编写的提示信息现在有时可能会产生意想不到的结果:之前的版本对指令的解释较为宽泛,甚至完全跳过某些部分,而 Opus 4.7 则会严格按照指令执行。用户应据此调整提示信息和相关设置。
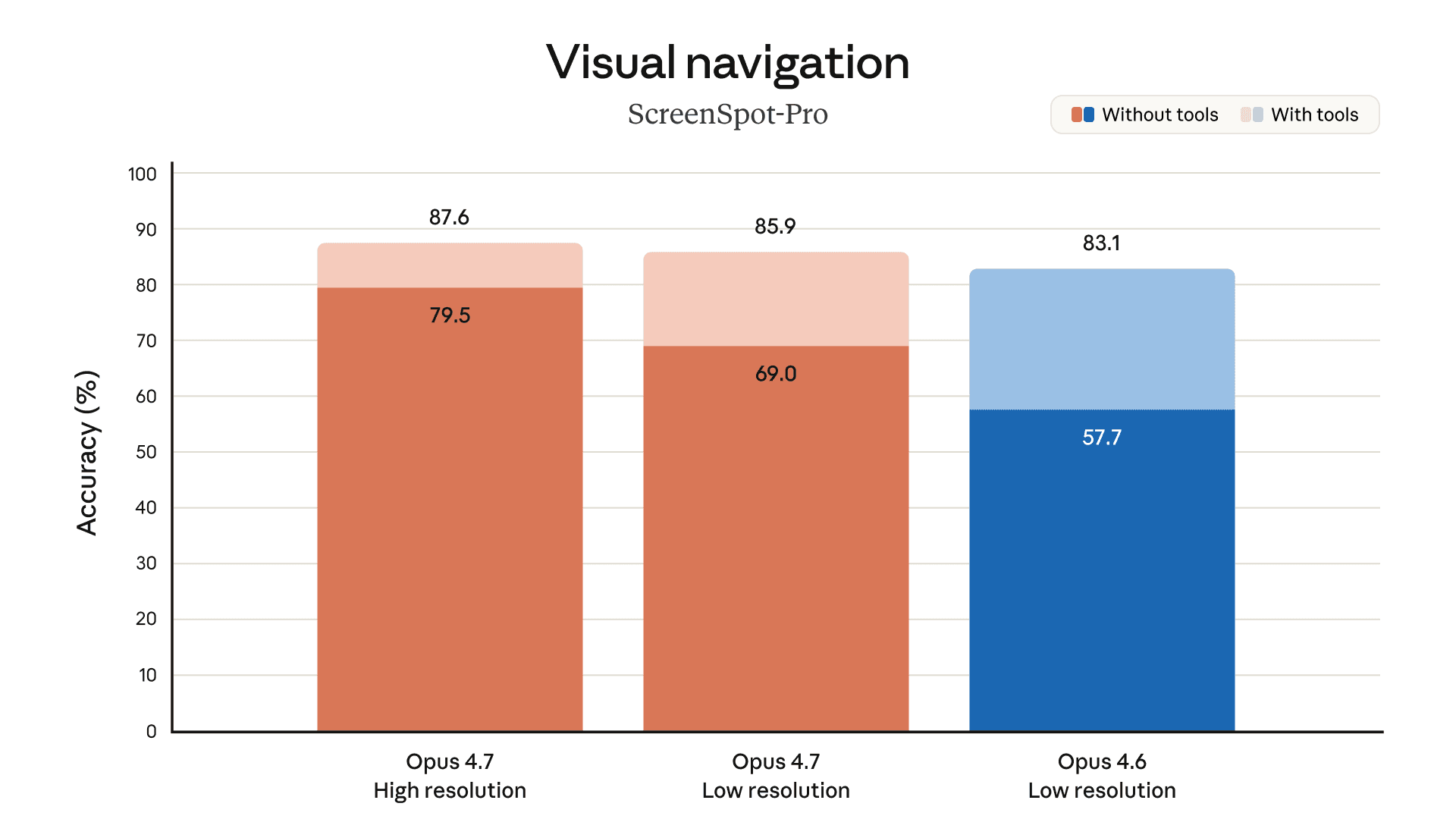
改进的多模态支持。Opus 4.7 对高分辨率图像的处理能力更强:它可以处理长边高达 2,576 像素(约 375 万像素)的图像,是之前 Claude 型号的三倍以上。这为依赖精细视觉细节的多模态应用开辟了广阔的空间:例如,计算机代理读取密集屏幕截图、从复杂图表中提取数据以及需要像素级精确参考的工作。
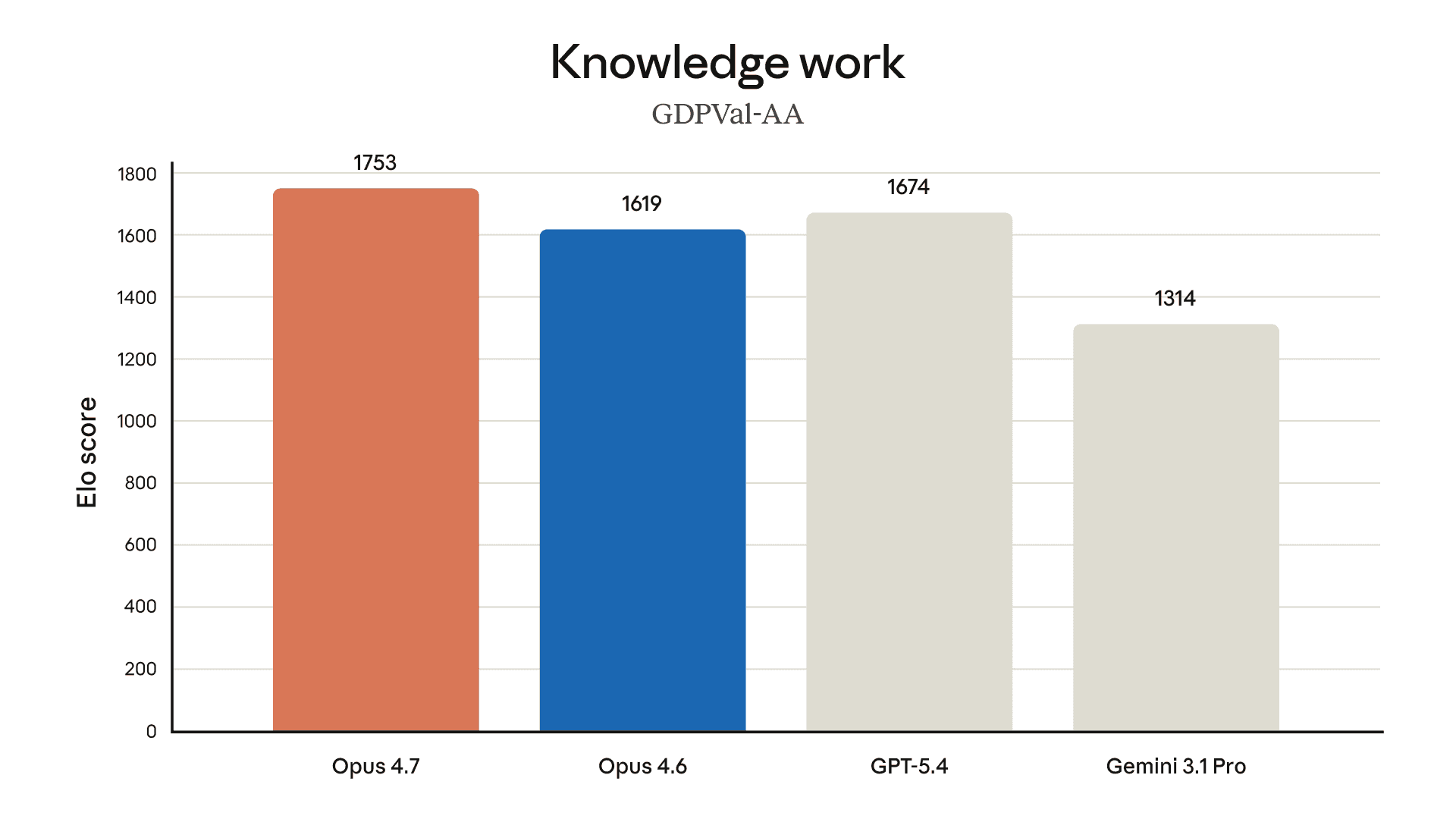
实际应用。除了在财务代理评估中获得领先水平(见上表)外,我们的内部测试表明,Opus 4.7 比 Opus 4.6 更高效地进行财务分析,能够生成严谨的分析和模型,呈现更专业的演示文稿,并在各项任务之间实现更紧密的整合。Opus 4.7 在GDPval-AA 评估中也处于领先水平,GDPval-AA是一项针对金融、法律及其他领域具有经济价值的知识工作的第三方评估。
内存方面,Opus 4.7 更擅长利用文件系统内存。它能记住长时间、多会话工作中的重要笔记,并利用这些笔记继续执行新的任务,因此这些新任务对预先获取的上下文信息要求更低。
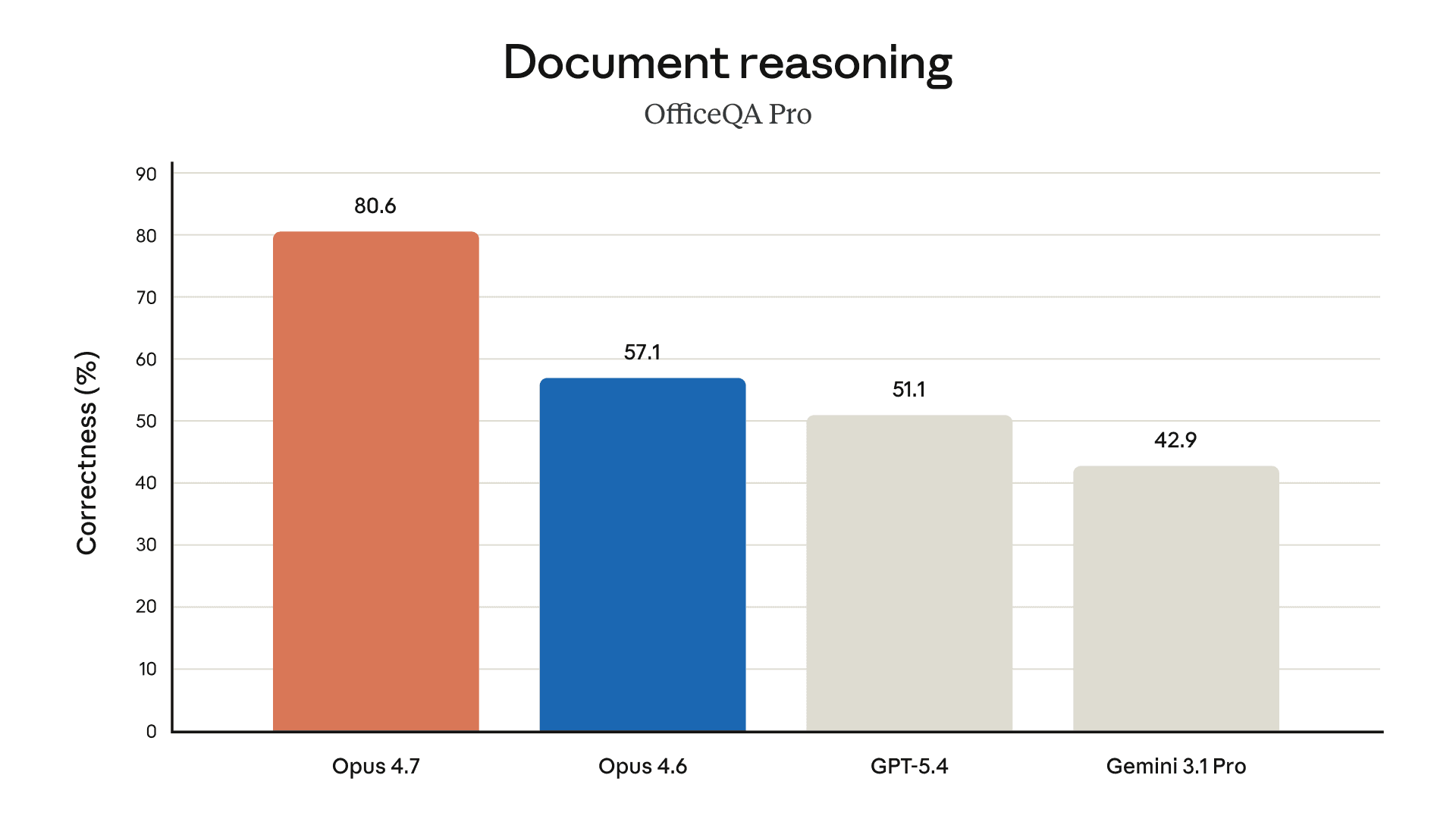
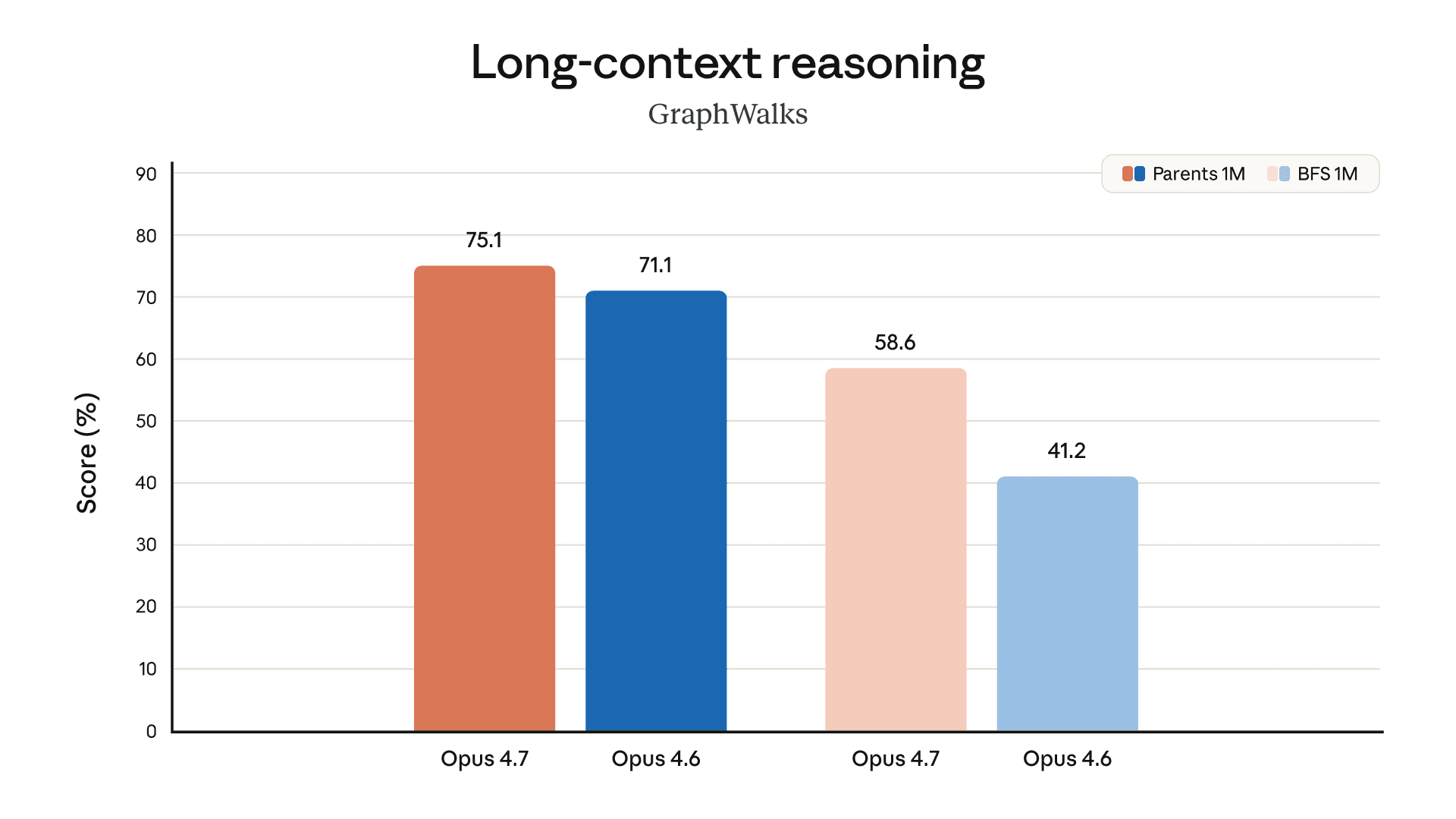
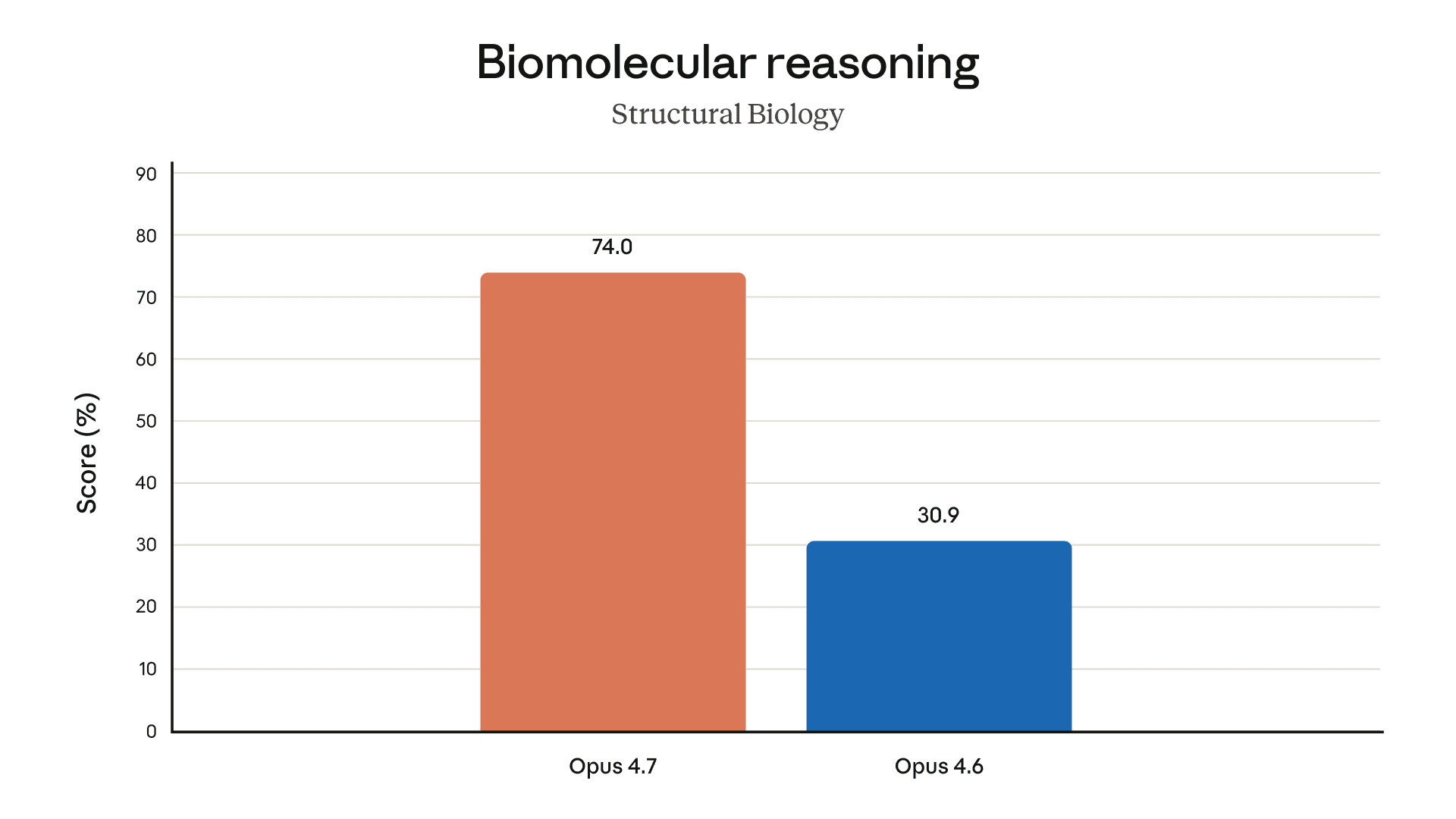
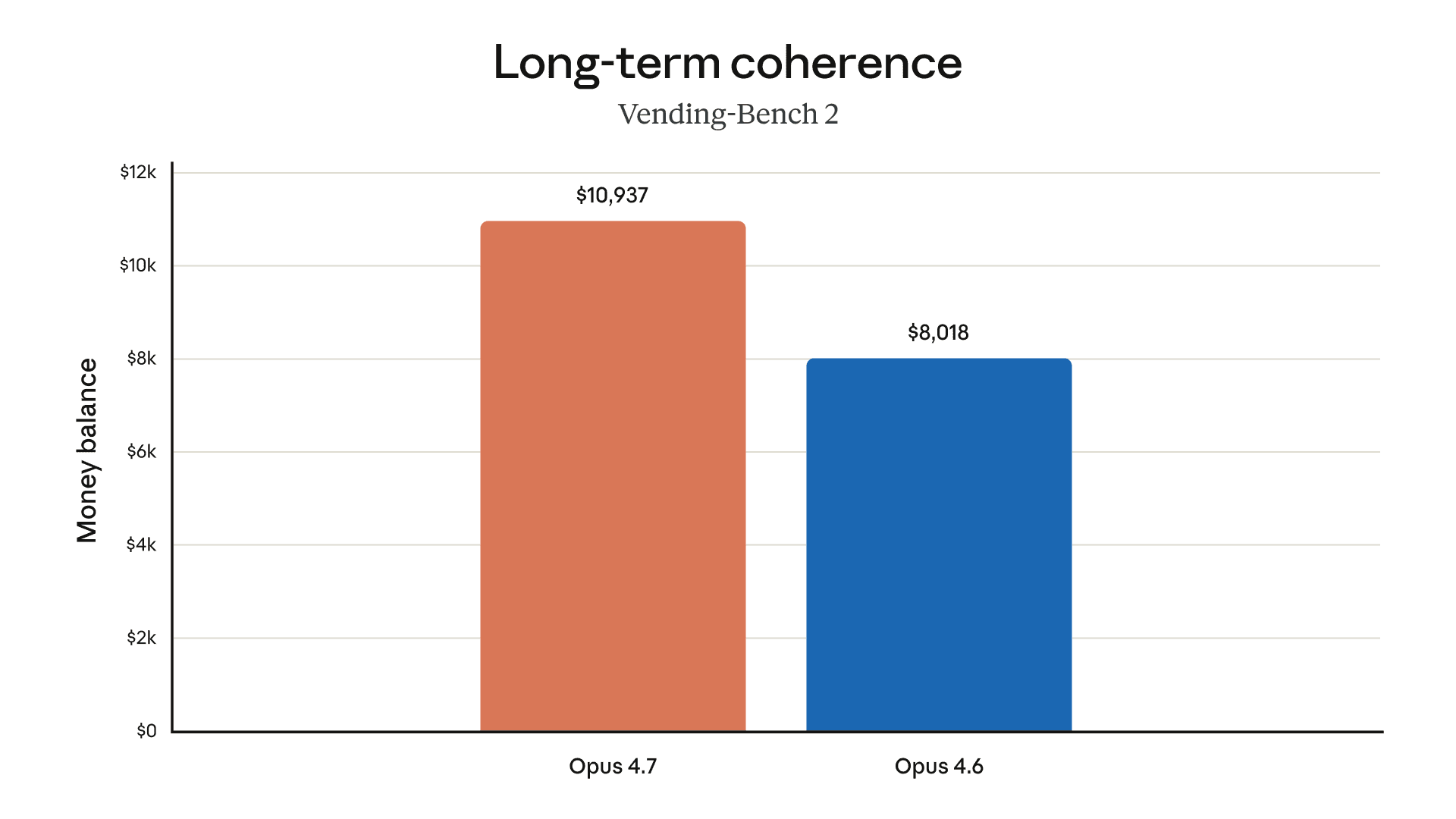
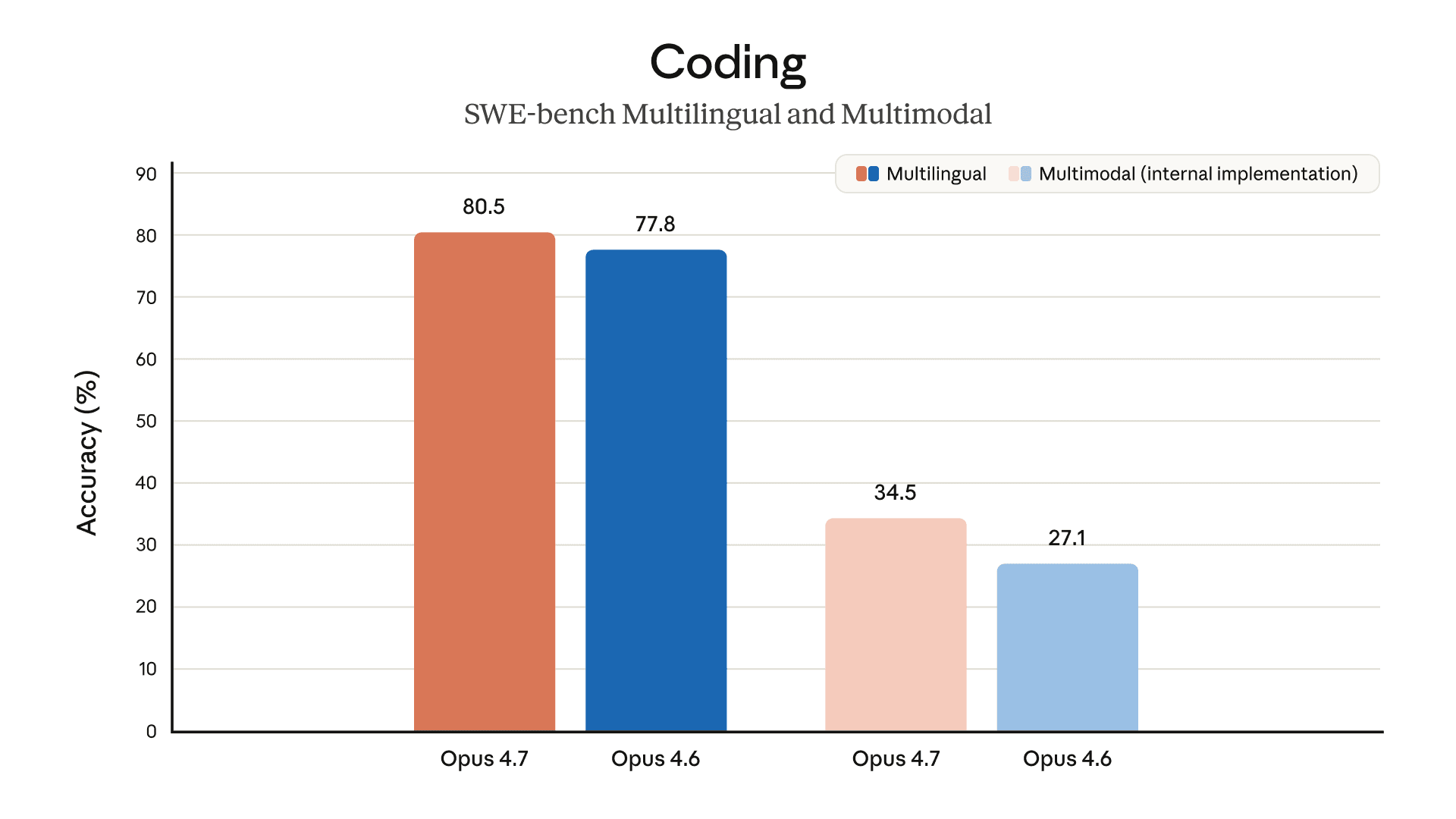
以下图表展示了我们在预发布测试中针对不同领域的更多评估结果:
办公任务想象文件推理长语境推理生物学长期一致性编码
安全与对齐
总体而言,Opus 4.7 的安全性能与 Opus 4.6 相似:我们的评估显示,其出现欺骗、奉承和与滥用者合作等令人担忧的行为的比例较低。在某些指标上,例如诚实度和抵御恶意“快速注入”攻击的能力,Opus 4.7 比 Opus 4.6 有所改进;但在其他指标上(例如其在管制药物方面提供过于详细的减害建议的倾向),Opus 4.7 略有不足。我们的一致性评估得出结论,该模型“总体上一致性良好且值得信赖,但其行为并非完全理想”。值得注意的是,根据我们的评估,Mythos Preview 仍然是我们训练过的一致性最佳的模型。我们的安全评估在Claude Opus 4.7 系统卡中有详细说明。
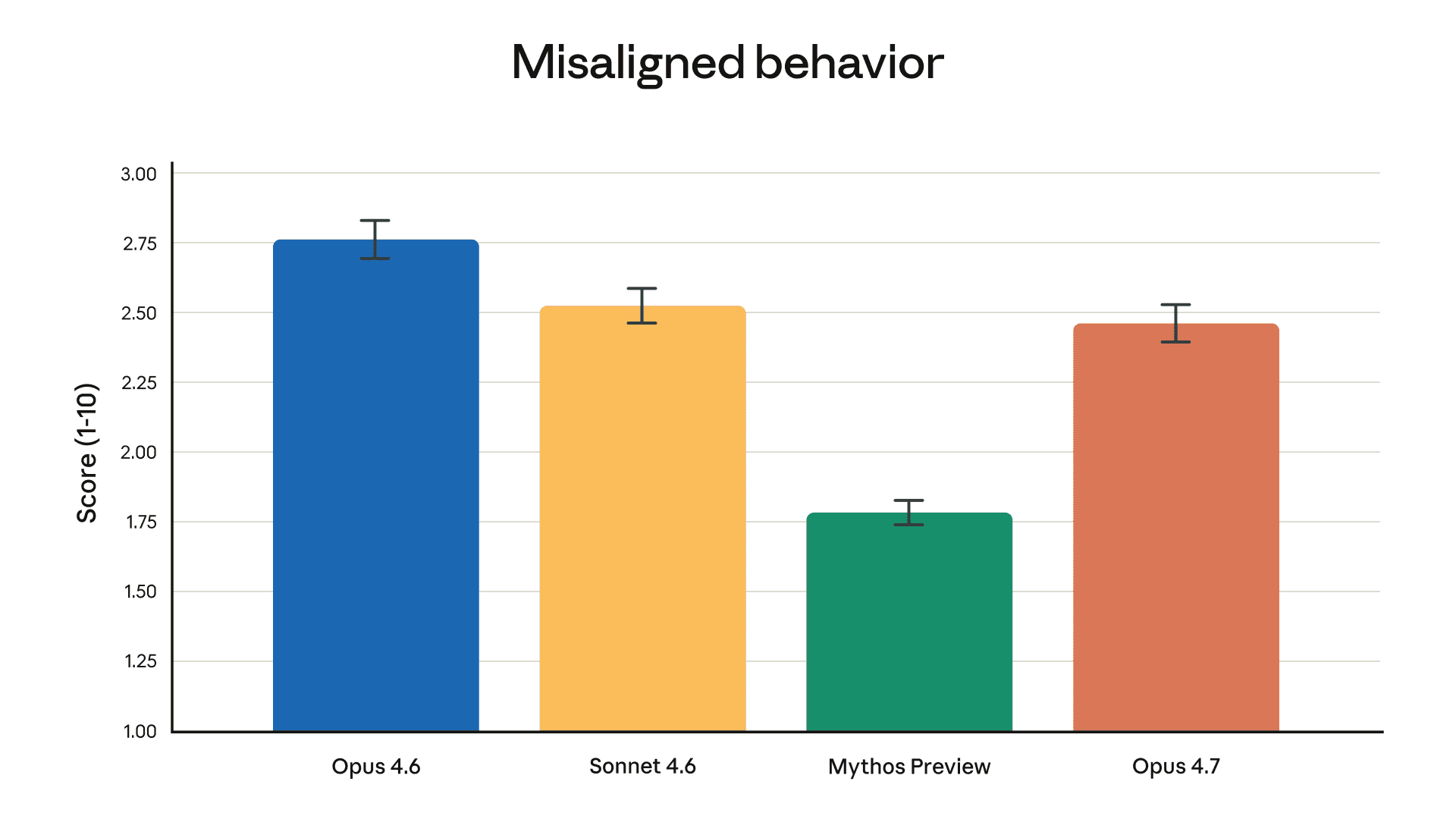
根据我们的自动化行为审核,总体行为偏差得分如下。在此评估中,Opus 4.7 相较于 Opus 4.6 和 Sonnet 4.6 略有改进,但 Mythos Preview 的行为偏差率仍然最低。
今天也同步推出。
除了 Claude Opus 4.7 本身之外,我们还将推出以下更新:
更精细的难度控制:Opus 4.7 新增了一个介于和之间的xhigh“超高”难度级别,使用户能够更精确地控制在解决难题时推理速度和延迟之间的权衡。在 Claude Code 中,我们已将所有套餐的默认难度级别提升至。在测试 Opus 4.7 的编码和智能体应用场景时,我们建议从或难度级别开始。highmaxxhighhighxhigh
在 Claude 平台(API)上:除了支持更高分辨率的图像外,我们还在公开测试版中推出了任务预算,让开发者能够引导 Claude 的代币支出,以便它可以优先处理较长时间内的工作。
在 Claude Code 中:新增的/ultrareview 斜杠命令会创建一个专门的审查会话,读取所有更改并标记出细心的审查员能够发现的错误和设计问题。我们为 Claude Code Pro 和 Max 用户提供三次免费的超强审查机会,供他们试用。此外,我们还将自动模式扩展到了 Max 用户。自动模式是一项新的权限选项,Claude 会代表您做出决策,这意味着您可以运行更长时间的任务,减少中断,并且比您选择跳过所有权限的风险更低。
从作品 4.6 迁移到作品 4.7
Opus 4.7 是 Opus 4.6 的直接升级版,但有两个变化值得关注,因为它们会影响词元的使用。首先,Opus 4.7 使用了更新的分词器,改进了模型处理文本的方式。但代价是,相同的输入可能会映射到更多的词元——根据内容类型的不同,大约增加 1.0 到 1.35 倍。其次,Opus 4.7 在高难度任务下会进行更多思考,尤其是在主动语态场景的后期回合。这提高了模型在解决难题时的可靠性,但也意味着它会产生更多的输出词元。
用户可以通过多种方式控制令牌使用:例如使用工作量参数、调整任务预算或引导模型简化代码。在我们自己的测试中,最终效果是积极的——内部编码评估显示,所有工作量级别的令牌使用率均有所提高(如下所示)——但我们建议在实际流量上进行评估。我们编写了一份迁移指南,其中提供了从 Opus 4.6 升级到 Opus 4.7 的更多建议。
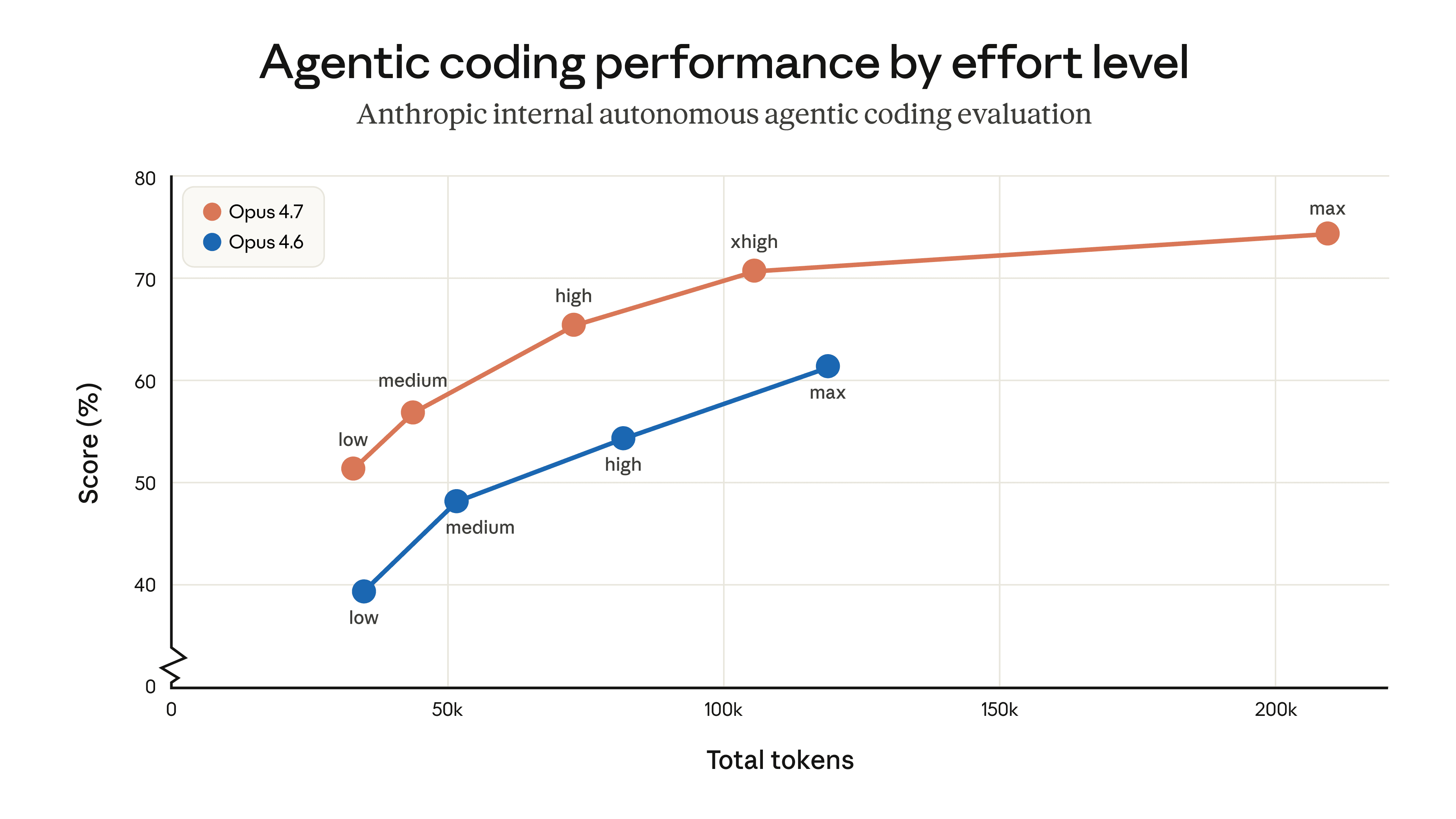
根据每个工作量级别下令牌使用情况,对内部智能体编码进行评估并得分。在此评估中,模型在单个用户提示下自主运行,因此结果可能无法代表交互式编码中的令牌使用情况。有关调整工作量级别的更多信息,请参阅迁移指南。
脚注
1这是模型层面的更改,而非 API 参数的更改,因此用户发送给 Claude 的图像将以更高的保真度进行处理。由于高分辨率图像会消耗更多令牌,因此不需要额外细节的用户可以在将图像发送给模型之前对其进行降采样。
对于 GPT-5.4 和 Gemini 3.1 Pro,我们在图表和表格中与通过 API 提供的最佳报告模型版本进行了比较。
MCP-Atlas:Opus 4.6 评分已更新,以反映 Scale AI 修订后的评分方法。
SWE-bench 已验证、专业版和多语言版:我们的记忆筛选功能会在这些 SWE-bench 评估中标记出一部分问题。排除所有显示出记忆痕迹的问题后,Opus 4.7 相对于 Opus 4.6 的改进幅度依然存在。
终端测试平台 2.0:我们使用了 Terminus-2 测试平台,并禁用了思维功能。所有实验均采用 1 倍保证资源分配/3 倍上限资源分配,每个任务取五次尝试的平均值。
CyberGym: Opus 4.6 的得分已从最初报告的 66.6 更新为 73.8,因为我们更新了测试参数以更好地激发网络能力。
SWE-bench 多模态:我们对 Opus 4.7 和 Opus 4.6 都使用了内部实现。得分与公开排行榜得分没有直接可比性。
评论
0 条登录后才可以发表评论。
立即登录