



隆重推出 Muse Spark:迈向个人超级智能
#新科技应用 时间2026-04-13 10:02:23

今天,我们很高兴地推出 Muse Spark,这是 Meta Superintelligence Labs 开发的 Muse 系列模型中的首款产品。Muse Spark 是一款原生多模态推理模型,支持工具使用、可视化思维链和多智能体协调。
Muse Spark 是我们扩展规模的第一步,也是我们人工智能业务彻底改革后的首个产品。为了支持进一步的扩展,我们正在对整个技术栈进行战略性投资——从研究和模型训练到基础设施,包括 Hyperion 数据中心。
在本文中,我们将首先探索 Muse Spark 的新功能和应用。在此之后,我们将深入分析推动我们迈向个人超级智能的扩展维度。
Muse Spark 现已在meta.ai和 Meta AI 应用上线。我们同时面向部分用户开放私有 API 预览。
个人超级智能的能力
Muse Spark 在多模态感知、推理、健康和智能体任务方面均展现出卓越的性能。我们将继续投资于目前性能尚有差距的领域,例如长时程智能体系统和编码工作流程。
随着更大模型的开发,这些结果表明我们的技术栈能够有效地扩展。
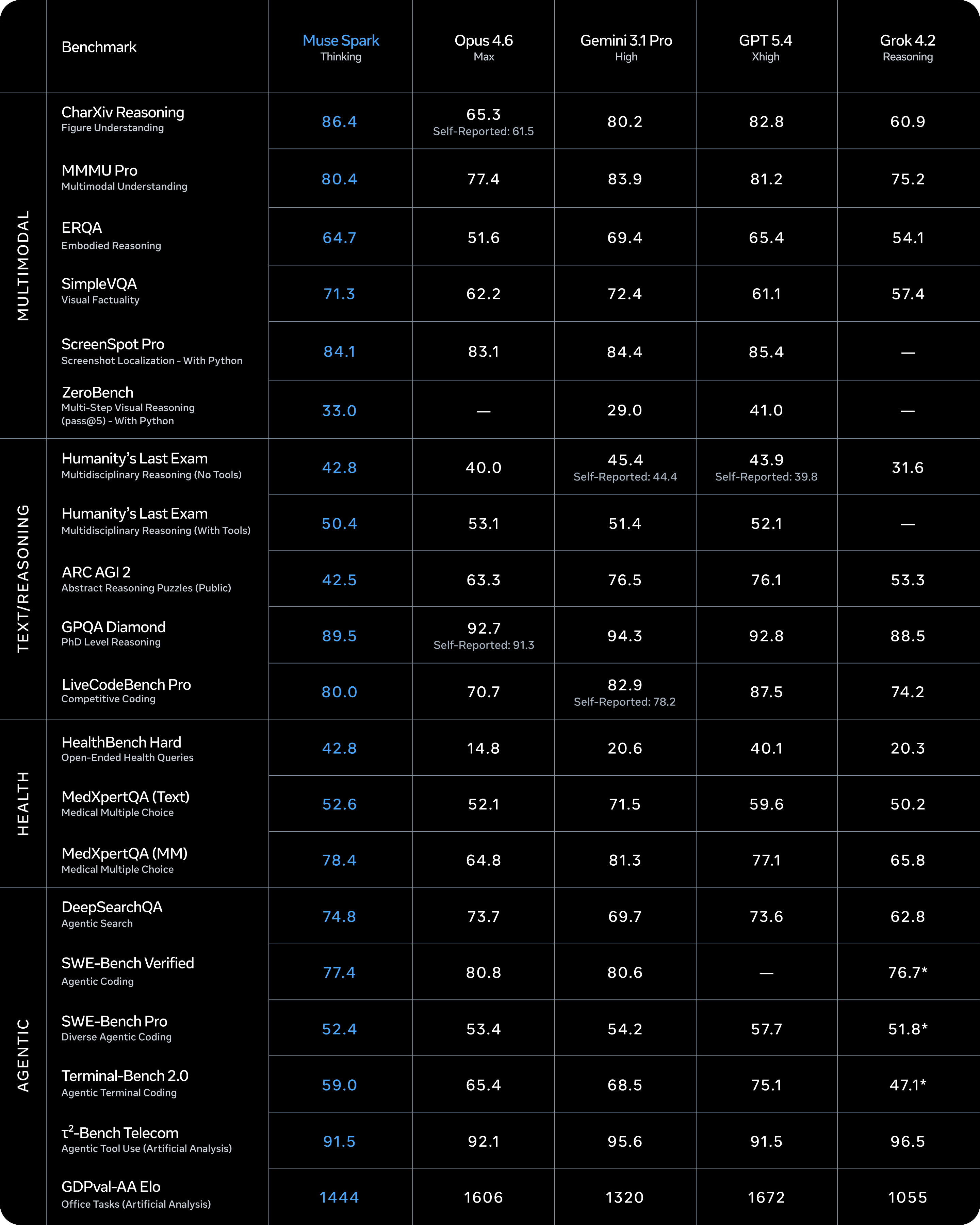
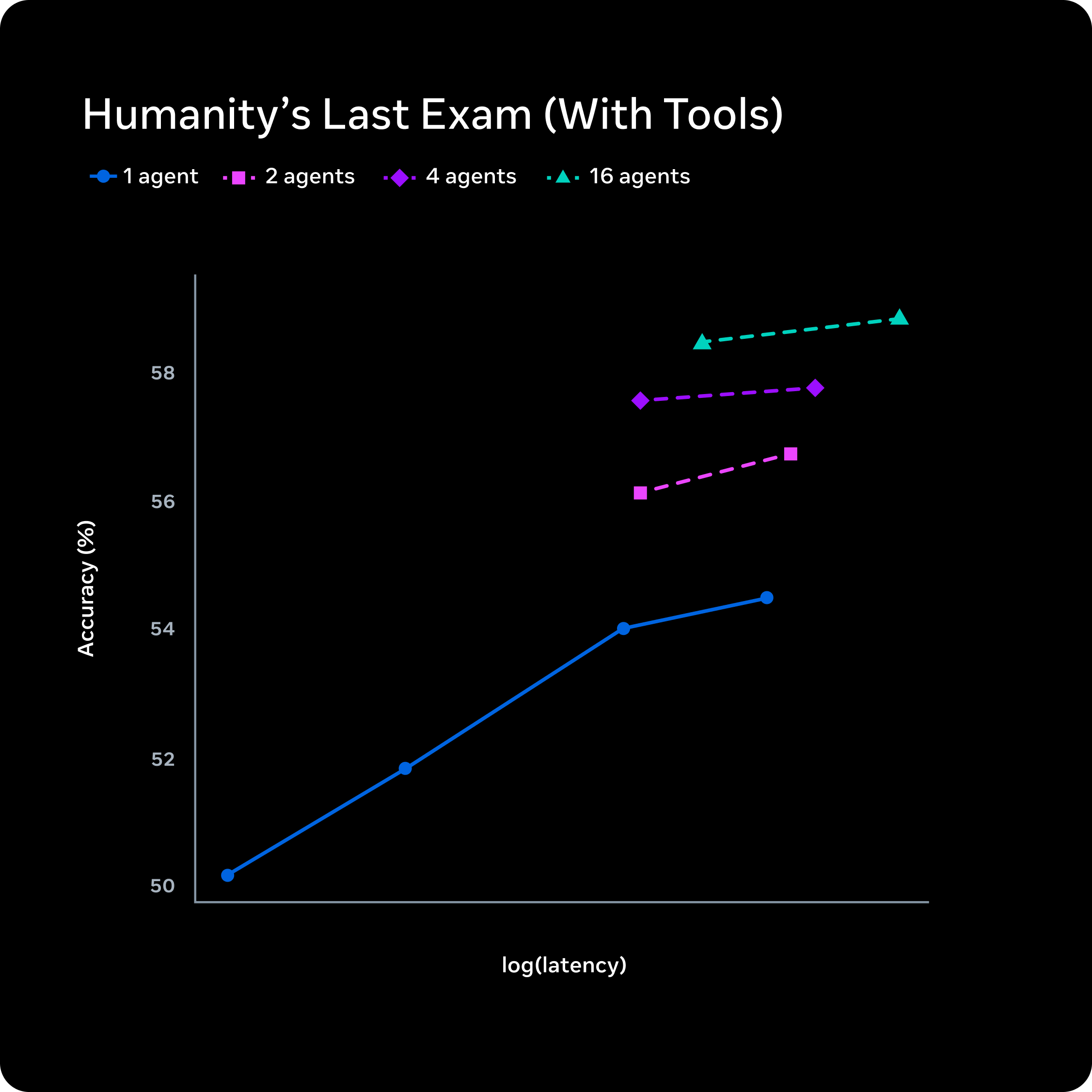
我们还发布了“思考模式”,该模式可协调多个智能体并行推理。这使得 Muse Spark 能够与 Gemini Deep Think 和 GPT Pro 等前沿模型的极限推理模式相媲美。“思考模式”显著提升了 Muse Spark 在挑战性任务中的能力,在“人类最后的考试”任务中取得了 58% 的完成率,在“前沿科学研究”任务中取得了 38% 的完成率。
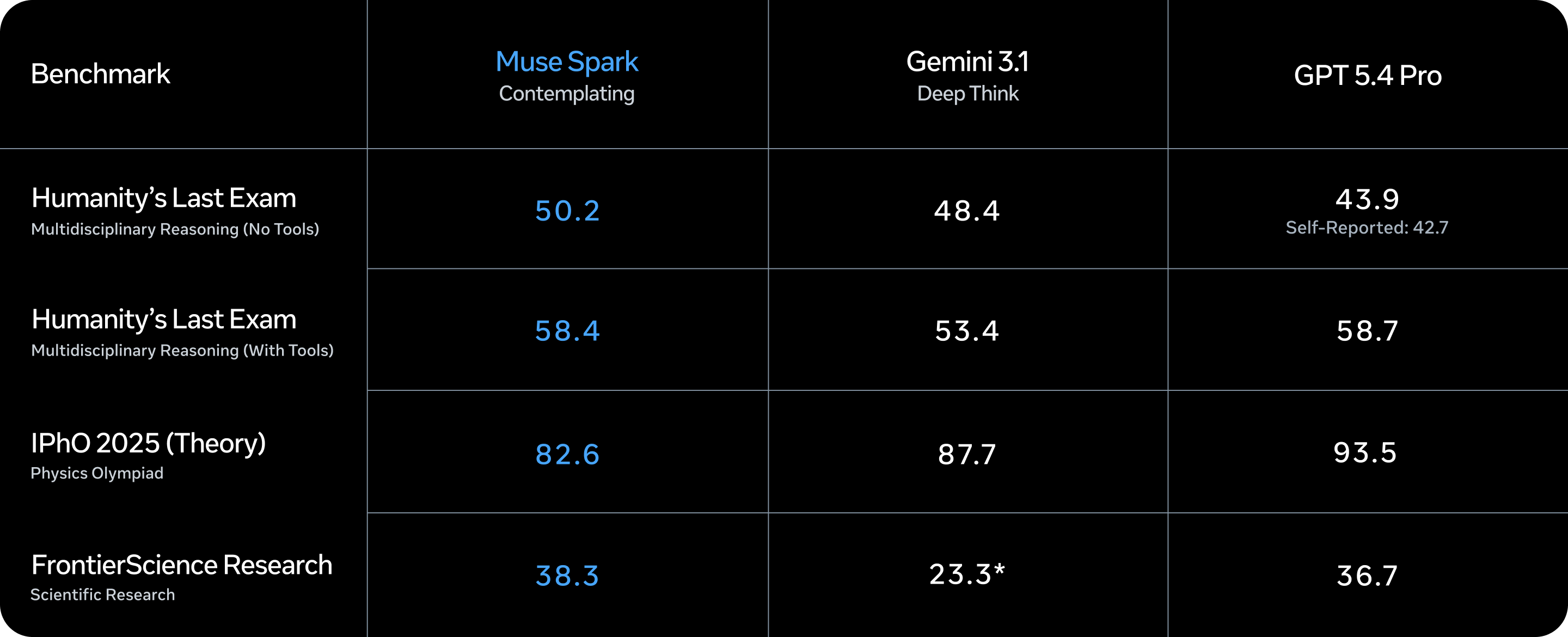
Muse Spark 现已推出,沉思模式将在meta.ai中逐步推出。
*有关我们评估的更多详细信息,请参阅我们的方法论文件。
应用程序
Muse Spark 是迈向个人超级智能的第一步,它能够理解你的世界。从分析你周围的环境到维护你的身心健康,Muse Spark 的高级推理能力能够实现强大且高度个性化的应用场景。
多模态。Muse Spark 从底层架构开始就旨在整合跨领域和工具的视觉信息。它在视觉 STEM 问题、实体识别和定位方面表现出色。这些功能结合起来,可以实现各种交互式体验,例如创建趣味小游戏或使用动态注释来排查家用电器故障。
健康。个人超智能的一项重要应用是帮助人们了解并改善自身健康状况。为了提升 Muse Spark 的健康推理能力,我们与 1000 多位医生合作,收集训练数据,从而实现更客观、更全面的反馈。Muse Spark 可以生成交互式显示界面,详细解读各种食物的营养成分或运动过程中激活的肌肉等健康信息。
提示:你能把它转换成一个我可以在网上玩的数独游戏吗?
提示:我是一名高胆固醇的鱼素者。请在推荐食物上标出绿色圆点,在不推荐食物上标出红色圆点。圆点不要重复,并确保位置正确。鼠标悬停在圆点上时,显示个性化的推荐理由和10分制的“健康评分”,以及卡路里、碳水化合物、蛋白质和脂肪含量。健康评分数字应在未悬停时显示在圆点上方。鼠标悬停时显示的描述应位于所有其他圆点之上。
刻度轴
为了构建个人超级智能,我们模型的性能必须能够以可预测且高效的方式扩展。下文将介绍我们如何从三个维度研究和追踪 Muse Spark 的扩展特性:预训练、强化学习和测试时推理。
预训练。在预训练阶段,Muse Spark 获得其核心的多模态理解、推理和编码能力——这是强化学习和测试时计算的基础。
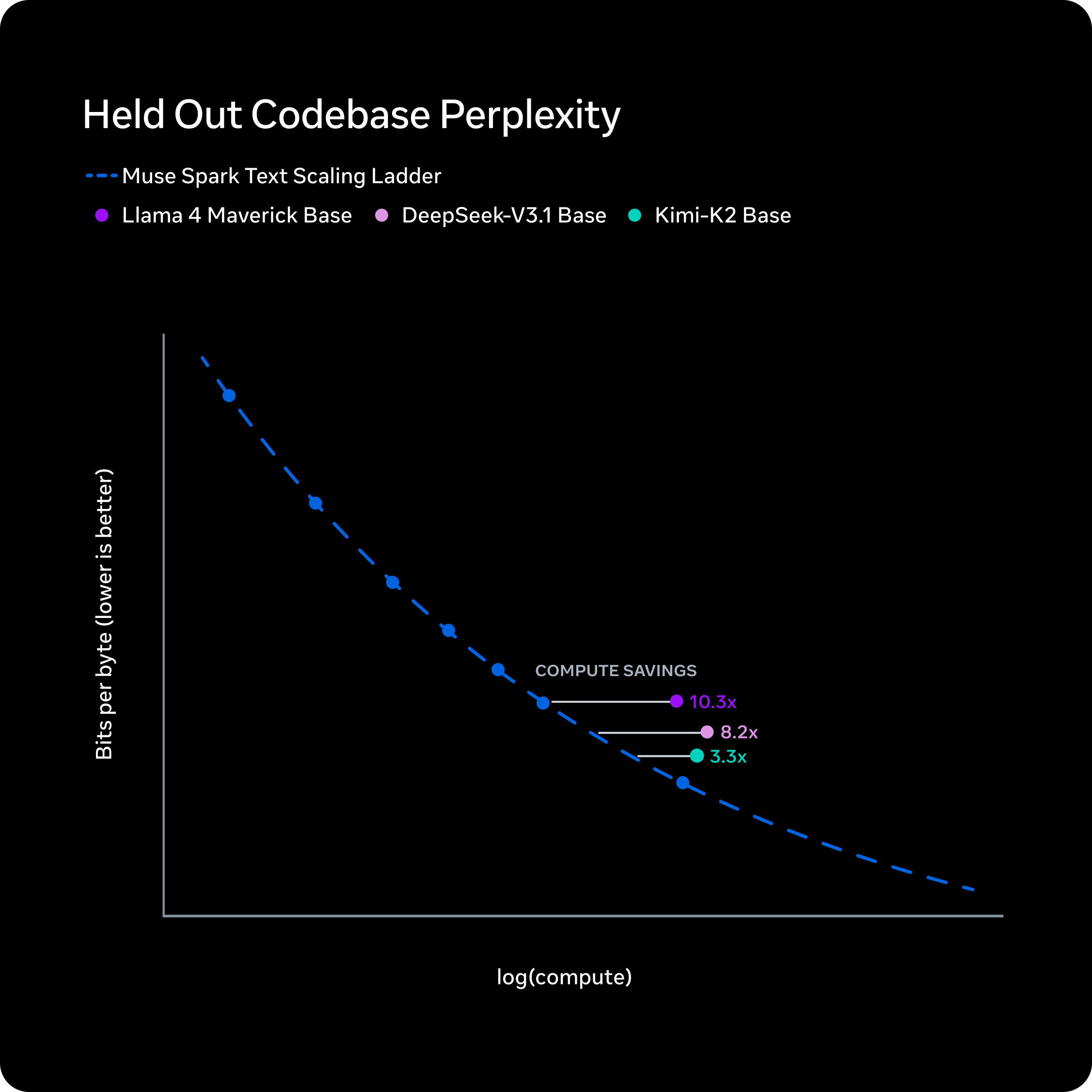
在过去的九个月里,我们重构了预训练堆栈,改进了模型架构、优化和数据管理。这些改进共同提升了我们利用每一单位计算资源所能达到的性能。为了严格评估我们的新方案,我们对一系列小型模型拟合了一个扩展定律,并比较了达到特定性能水平所需的训练浮点运算次数(FLOPs)。结果显而易见:与之前的模型 Llama 4 Maverick 相比,我们用少一个数量级以上的计算资源就能达到相同的性能。这一改进也使得 Muse Spark 比目前可供比较的领先基础模型效率更高。
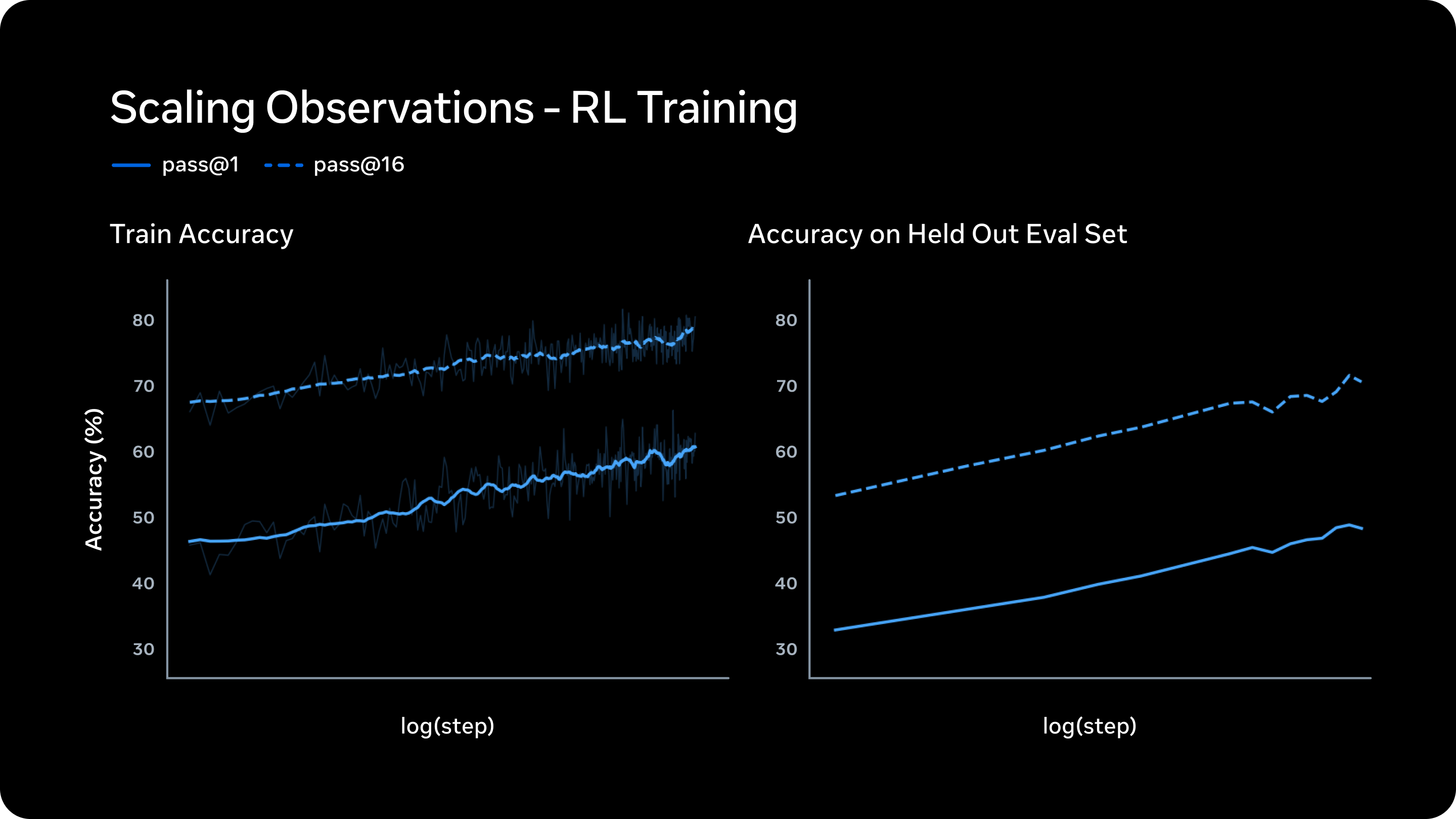
强化学习。经过预训练后,强化学习 (RL) 利用计算能力可扩展地提升模型性能。尽管大规模强化学习历来容易出现不稳定,但我们的新技术栈能够带来平稳、可预测的性能提升。
下图展示了扩展 Muse Spark 的强化学习 (RL) 计算能力(以步数衡量)所带来的益处。左图显示,在训练数据上,pass@1 和 pass@16(16 次尝试中至少成功一次)的数值呈对数线性增长。这表明强化学习在不影响推理多样性的前提下提高了模型的可靠性。右图显示,在预留的评估集上准确率的增长表明,强化学习带来的收益具有可预测的泛化能力:Muse Spark 在训练中未遇到的任务上也表现良好。
测试时推理。强化学习训练模型在回答问题前进行“思考”——这一过程被称为测试时推理。要让数十亿用户拥有这种能力,就需要高效利用推理令牌。为此,我们依靠两个关键手段:一是思考时间惩罚,用于优化令牌使用;二是多智能体编排,用于在不降低响应速度的前提下提升性能。
为了在每个词元上实现最高的智能水平,我们的强化学习训练在增加思考时间的前提下,最大化正确率。在诸如 AIME 等部分评估任务中,这会导致阶段性转变。在初始阶段,模型通过延长思考时间来提升性能;之后,思考时间的惩罚会促使模型进行思维压缩——Muse Spark 会压缩其推理过程,从而使用更少的词元解决问题。压缩之后,模型会再次扩展其解决方案,以获得更强的性能。
为了在不显著增加延迟的情况下,将更多时间用于测试时的推理,我们可以扩展协作解决难题的并行智能体的数量。下图展示了这种方法的优势。标准的测试时扩展方法会使单个智能体思考更长时间,而采用多智能体思维的 Muse Spark 扩展方法则可以在保持相当延迟的情况下实现更高的性能。
安全
Muse Spark 在军民两用科学领域拥有广泛的推理能力,因此我们在部署前进行了全面的安全评估。我们的流程遵循更新后的高级人工智能扩展框架 (Advanced AI Scaling Framework),该框架定义了我们最先进模型的威胁模型、评估协议和部署阈值。我们在应用针对前沿风险类别、行为一致性和对抗鲁棒性的安全缓解措施前后,分别对 Muse Spark 进行了评估。
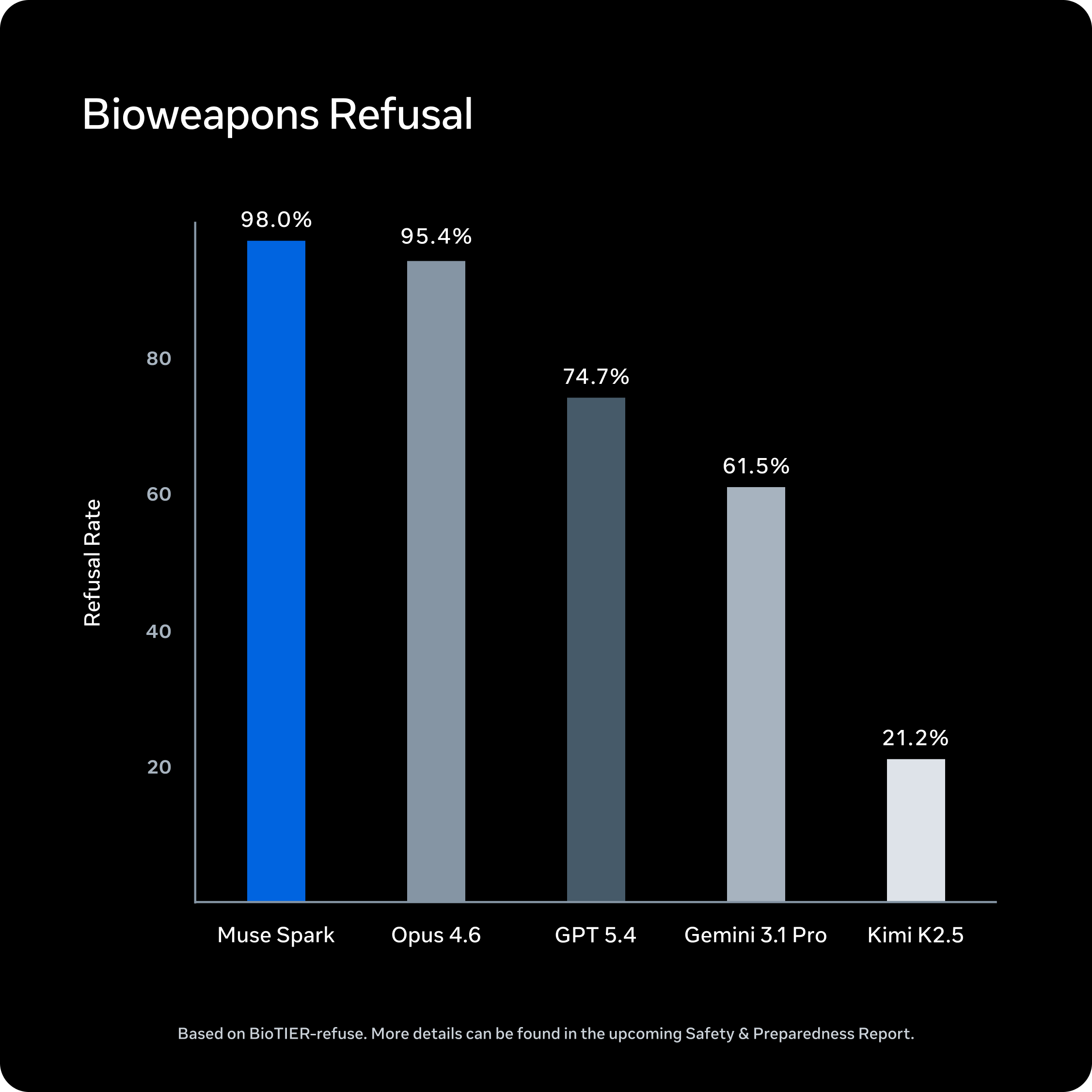
我们发现,Muse Spark 在生物和化学武器等高风险领域表现出强烈的拒绝行为,这得益于预训练数据过滤、以安全为中心的后训练以及系统级防护措施。在网络安全和失控领域,Muse Spark 不具备实现威胁场景所需的自主能力或危险倾向。我们的评估表明,鉴于其部署环境,Muse Spark 在我们评估的所有前沿风险类别中均处于安全范围内。完整结果将在即将发布的《安全与准备报告》中公布。
在一次接近发射的检查点上,阿波罗研究公司进行的第三方评估发现,Muse Spark 模型展现出了他们所观察过的模型中最高的评估意识水平。该模型经常将某些场景识别为“对齐陷阱”,并认为既然正在接受评估,就应该诚实地行事。这一点至关重要,因为能够识别评估环境的模型在测试和部署过程中可能会表现出不同的行为。然而,这些结果并未证实评估意识会直接改变模型的行为。我们后续的调查也发现了一些初步证据,表明评估意识可能会在一小部分对齐评估中影响模型的行为,而这些评估均与影响模型发射决策的危险能力或倾向无关。我们认为这并非阻碍模型发布的因素,但仍需进一步研究。更多详情请阅读我们即将发布的《安全与准备报告》。
结论
借助 Muse Spark,我们正走上一条可预测且高效的扩展之路。我们期待着在迈向个人超级智能的道路上,尽快分享功能日益强大的模型。
评论
0 条登录后才可以发表评论。
立即登录