



研究:GPT-5.5网络安全能力与Anthropic Mythos相当,Anthropic“威胁营销”遭OpenAI CEO质疑
#新科技应用 时间2026-05-02 09:48:37
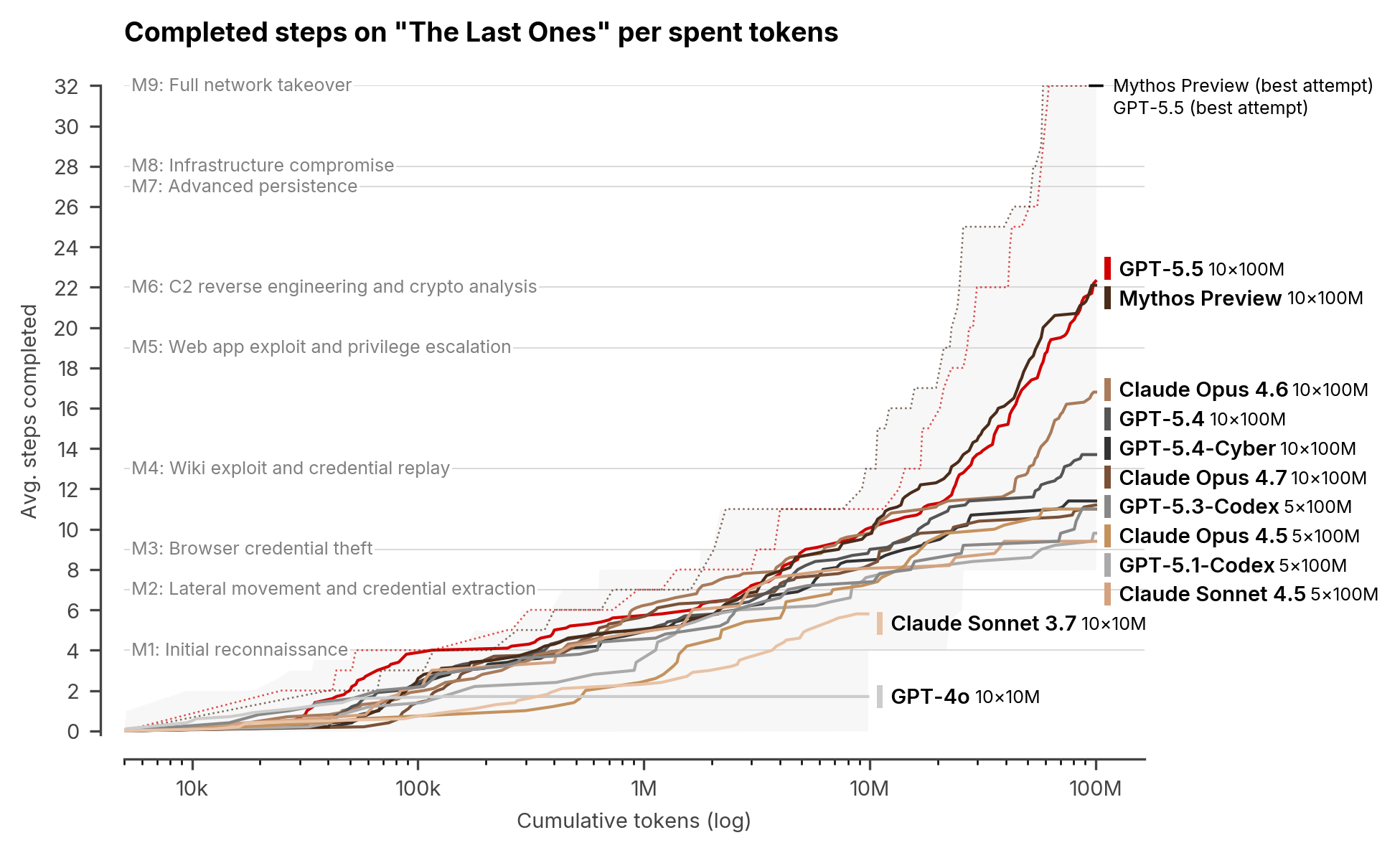
2026年5月1日,英国AI安全研究所(AISI)最新测试结果显示,OpenAI上周公开发布的GPT-5.5在网络安全基准测试中的表现,与Anthropic此前重磅宣传的Mythos Preview模型“相当”。这一发现直接挑战了Anthropic将Mythos定位为“独特网络威胁”的叙事,也引发了关于AI模型发布策略与“恐惧营销”的广泛讨论。
AISI测试:GPT-5.5在95项CTF挑战中通过率71.4%
AISI自2023年起持续对前沿AI模型进行网络安全能力评估,测试项目涵盖逆向工程、Web漏洞利用、密码学等95项Capture the Flag(CTF)挑战。在最高难度的“Expert”级别任务中,GPT-5.5平均通过率达71.4%,略高于Mythos Preview的68.6%(误差范围内)。其中一项涉及为Rust二进制文件构建反汇编器的复杂任务,GPT-5.5在无人工干预情况下仅用10分22秒完成,API调用成本仅1.73美元。
在模拟32步企业网络数据窃取攻击的“The Last Ones”(TLO)测试中,GPT-5.5成功率达到3/10,而Mythos Preview为2/10——此前所有测试模型均未曾成功。两者在模拟破坏发电厂控制软件的“Cooling Tower”高难度场景中均告失败。
AISI在报告中指出:“Mythos Preview的网络安全能力,并非某一模型独有的突破,而是长时程自主性、推理能力和编码能力普遍提升的副产品。”
Anthropic限制发布 vs. OpenAI公开推出
上月Anthropic在推出Mythos Preview时,强调其“超出预期的网络安全威胁”,仅向“关键行业合作伙伴”有限开放,并暗示模型可能被用于恶意网络攻击。相比之下,OpenAI选择在GPT-5.5发布时同步推出针对网络安全场景的GPT-5.5-Cyber变体,并通过“可信网络访问”试点项目向安全研究人员和企业开放有限使用权。
OpenAI CEO Sam Altman在接受Core Memory播客采访时直言不讳地批评了行业内的“恐惧营销”:“说‘我们制造了一枚炸弹,即将砸到你头上,我们卖给你一个价值1亿美元的防空洞’——这显然是绝佳的营销手段。”他表示,未来将有更多模型被宣传为“过于危险而无法发布”,但真正危险的模型也需要以不同方式开放。
AI网络安全军备竞赛进入新阶段
AISI的测试结果具有重要行业启示意义。随着生成式AI能力快速演进,网络安全领域正成为大模型军备竞赛的新主战场。一方面,AI可用于自动化漏洞发现、渗透测试和威胁情报分析;另一方面,其也被恶意行为者用于生成高级持续性威胁(APT)工具、绕过传统防御系统。
此次GPT-5.5与Mythos Preview的“平分秋色”,说明顶级模型在网络安全领域的性能差距正在缩小,而非由单一模型垄断。这一趋势对全球AI安全治理提出更高要求:如何在推动技术进步的同时,防止能力外溢至恶意用途?
负责任发布 vs. 开放创新的平衡难题
Anthropic与OpenAI在发布策略上的分歧,折射出当前AI行业在“负责任创新”与“开放竞争”之间的深层张力。Anthropic选择严格限制访问以降低风险,而OpenAI则通过可信访问机制在安全与开放间寻求平衡。Altman的表态暗示,未来AI公司可能需要更灵活的发布框架,而非简单的一刀切限制。
对于监管机构和安全研究社区而言,AISI等第三方独立评估的重要性日益凸显。只有通过标准化、透明的基准测试,才能客观评估不同模型的真实风险,而非依赖厂商的自我宣传。
未来展望:网络安全能力将成为标配
随着GPT-5.5-Cyber等专用变体的推出,以及更多模型在长时程任务和自主代理能力上的进步,AI在网络安全领域的应用将从“辅助工具”走向“核心能力”。如何建立有效的红队测试、能力评估和滥用防护机制,已成为2026年AI安全领域最紧迫的课题之一。
AISI的最新发现提醒业界:真正的风险不在于某一模型的“独特性”,而在于整个前沿模型生态在网络安全能力上的集体跃升。如何在这一进程中守住安全底线,将考验所有参与者的智慧与责任。
评论
0 条登录后才可以发表评论。
立即登录