



DeepSeek-V4系列震撼发布:百万token上下文高效MoE模型,开源新标杆
#新科技应用 时间2026-04-28 09:32:18
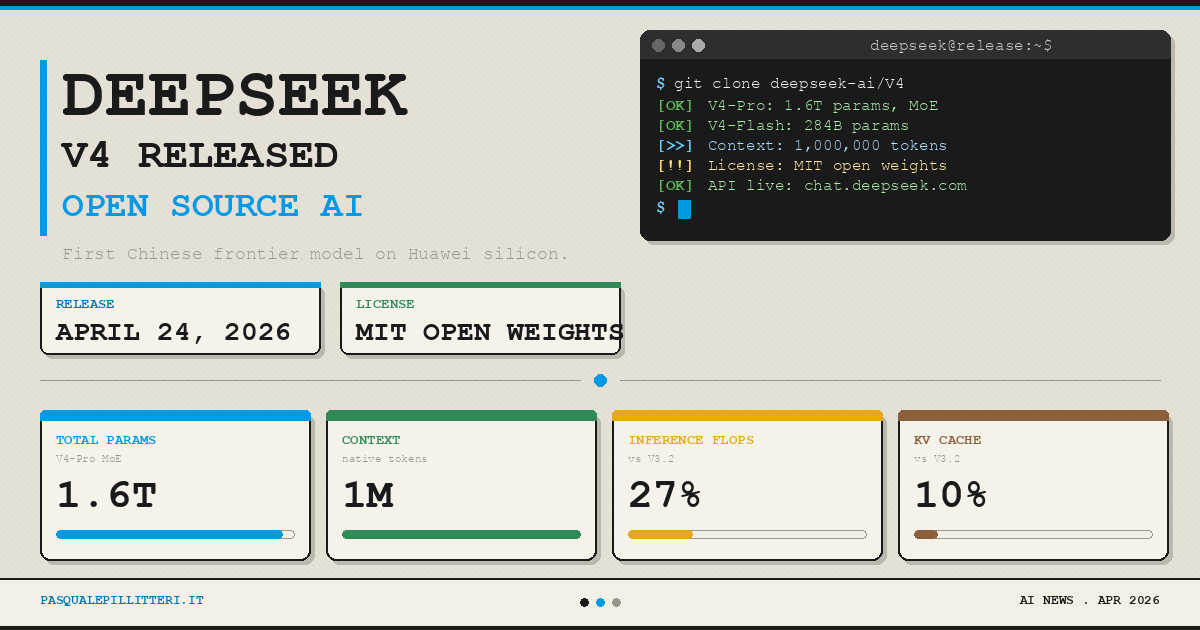
DeepSeek-AI于4月27日在Hugging Face正式推出DeepSeek-V4系列预览版,带来两款高性能Mixture-of-Experts(MoE)大语言模型:DeepSeek-V4-Pro(总参数1.6万亿,激活参数49B)和DeepSeek-V4-Flash(总参数284B,激活参数13B)。两款模型均原生支持100万token超长上下文,标志着开源模型在长序列处理效率上实现重大突破。
相比前代DeepSeek-V3.2,DeepSeek-V4系列在架构上进行了多项关键创新:引入混合注意力机制(Compressed Sparse Attention + Heavily Compressed Attention),大幅压缩KV缓存;采用Manifold-Constrained Hyper-Connections(mHC)升级残差连接,提升模型表达能力;同时首次大规模应用Muon优化器,实现更快的收敛速度和更高的训练稳定性。模型在超过32万亿高质量多样化token上完成预训练,随后经过全面的后训练流程,进一步释放和强化了推理、工具调用、代理等核心能力。
性能方面,DeepSeek-V4-Pro-Max(最大推理努力模式)在多项核心基准测试中刷新开源模型纪录,尤其在长上下文场景下表现出色。在100万token上下文环境中,其单token推理FLOPs仅为DeepSeek-V3.2的27%,KV缓存占用更是降至10%,让百万token长序列任务从“理论可能”真正走向“日常可用”。这一效率飞跃不仅为测试时扩展(test-time scaling)打开全新空间,也为复杂代理工作流、海量文档分析等长时程任务奠定坚实基础。
DeepSeek-V4系列继续沿用DeepSeekMoE框架与Multi-Token Prediction(MTP)策略,同时在训练基础设施上实现多项优化,包括专家并行中的精细通信-计算重叠、TileLang内核开发、FP4量化感知训练以及高效的上下文并行机制,确保训练与推理均具备极高性价比。
模型权重已开源至Hugging Face(MIT许可),开发者可立即下载部署。DeepSeek-AI表示,V4系列的百万token高效支持,将推动开源社区在长上下文智能、在线学习等前沿方向加速探索,助力下一代通用人工智能的实际落地。
这一发布再次巩固DeepSeek在高性价比开源大模型领域的领先地位,也为全球AI开发者提供了更强大、更高效的长上下文工具。后续版本迭代与完整技术报告值得持续关注。
评论
0 条登录后才可以发表评论。
立即登录