



在你的笔记本电脑上运行你自己的编码代理(免费)
#IAICA观察 时间2026-04-20 10:57:08
IAICA.com.cn----- https://app.therundown.ai/guides/run-your-own-coding-agent-on-your-laptop-for-free 2026年4月20日
在本指南中,您将学习如何使用 Ollama 将编码 LLM 下载到您的笔记本电脑,并通过一条命令将其连接到 Claude Code 或 Codex。
所需工具Ollama App
概要
本指南将教您如何使用 Ollama 将编码 LLM 下载到笔记本电脑,并通过一条命令将其集成到 Claude Code 或 Codex 中。您可以免费运行编码代理执行简单的任务,并将专有代码完全保留在自己的计算机上。
这适用于哪些人
独立开发者和创始人 每月花费 100-200 美元购买 Claude Code Max 或 Codex Pro,用于不需要前沿推理的工作。
学生、业余爱好者和 想要免费练习的代理系统搭建方案的新手程序员
任何从事专有代码或受保密协议约束的代码编写工作, 并且希望整个流程都保留在自己笔记本电脑上的人,都可能遇到这种情况。
你将建造什么
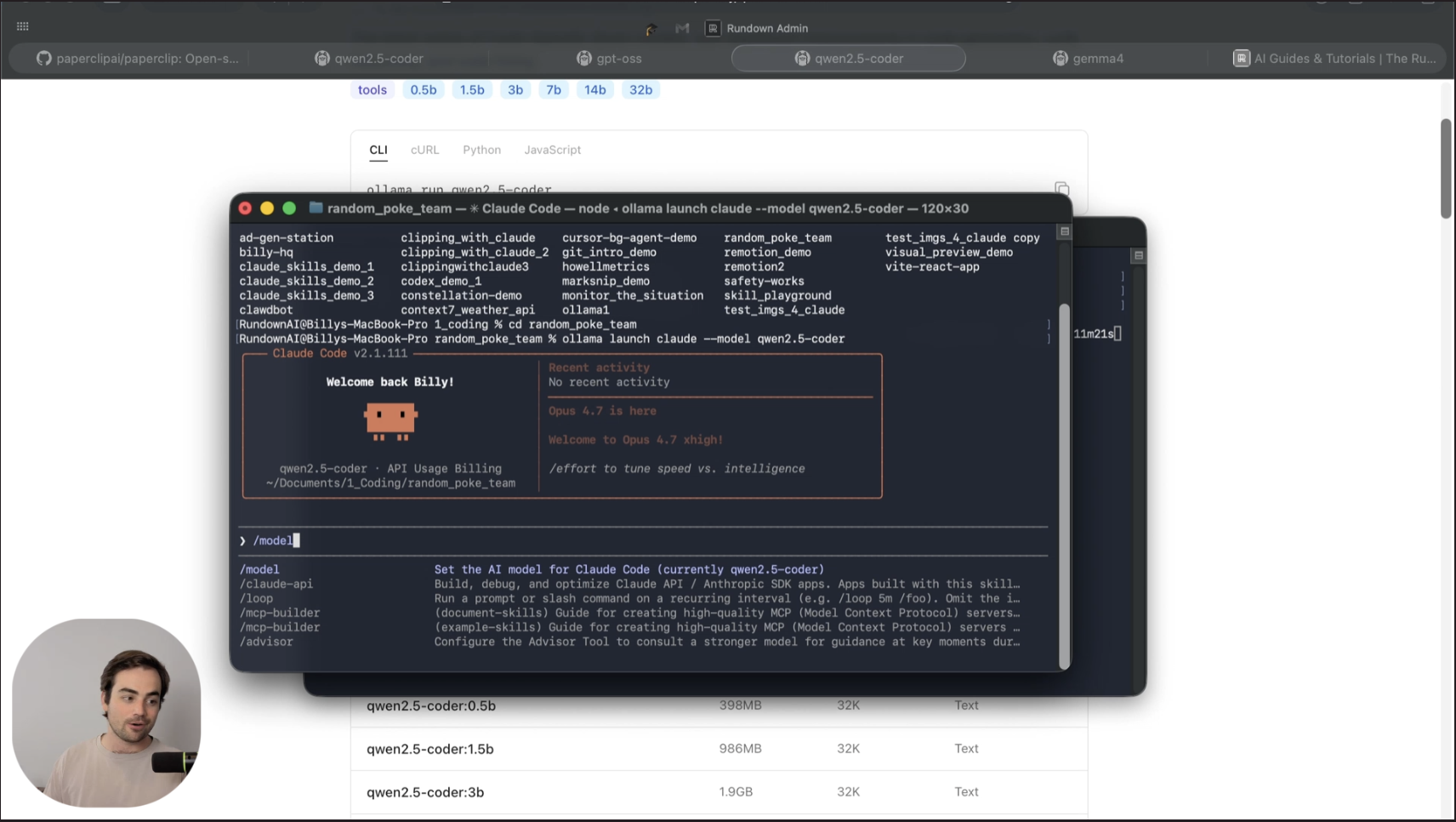
本地 Claude Code(或 Codex、OpenCode)会话指向运行在您本地硬件上的免费 Ollama 模型。相同的代理,相同的界面,零令牌成本,数据不会离开您的计算机。
入门所需物品
Ollama 已安装。如果您尚未安装,请先按照 我们的 Ollama 安装指南进行操作。
Claude Code 已登录并运行,或者 OpenCode(步骤 5 中的安装程序)
一个终端和一个你真正想工作的项目文件夹
16GB 内存是理想配置。8GB 内存适用于配置较低的机型。32GB 及以上更好。
步骤 1 检查您的硬件并咨询 LLM 要运行什么程序
在执行任何操作之前,请先了解您的计算机性能。在 Mac 上:苹果菜单 > 关于本机 > 截图规格面板。在 Windows 上: 设置 > 系统 > 关于 > 截图。
把截图导入 Claude、ChatGPT 或任何 LLM 工具,然后问:“我这台机器上可以用 Claude Code 或 Codex 运行哪些 Ollama 编码模型?” 它会读取 RAM 信息,并分析你的截图,然后给你一个简短的列表。
大致的适用范围指南:
你的内存 | 推荐尺寸 | 例子 |
8 GB | 3B 参数或更小 | qwen3-coder:3b |
12 GB | 4-7B 参数 | gemma4:e2b,qwen3-coder:7b |
16 GB | 7-12B 参数 | qwen3-coder:7b,gemma4:e4b |
32 GB+ 或 GPU | 20B+ | qwen3-coder:32b,,gpt-oss:20bgemma4:26b |
专业提示: 下载你能合理安装的最大版本。更大的版本意味着更可靠的工具调用,而这正是导致 Claude Code 中小型模型崩溃的真正原因。
步骤 2:选择支持代理工具的编码员模型
访问 ollama.com/search?q=coder ,打开您法学硕士课程推荐的模型页面。 关键检查: 滚动到模型页面的“应用程序”部分,确认其中列出了 Claude Code、Codex、OpenCode 或 OpenClaw。如果未列出任何这些工具,则表示该模型不支持代理编码所需的工具调用。请跳过此模型。
我们测试中表现最佳的三款产品:
qwen3-coder 是专为程序员打造的选择。它体积小巧,却拥有强大的原始代码生成能力。
gemma4 接受过专门的工具使用和思维训练。能够更可靠地处理多步骤工具链。
gpt-oss 是 OpenAI 的开放权重 MoE 模型,具有强大的智能体支持。
专业提示: 如果两个候选版本难以抉择,那就都下载下来。磁盘资源很便宜,而且你可以用设置 --model 选项在它们之间切换。最终保留那个真正符合你工作流程的版本。
步骤 3:使用本地模型启动您的编码代理
从模型的 Ollama 页面复制启动命令。命令格式如下:
ollama launch claude --modelgemma4:e4b

在项目文件夹中打开终端,粘贴命令,然后按回车键。出现提示时确认下载,然后等待权重首次加载完成。之后,Ollama 会将你导入到 Claude Code,并指向本地模型而不是 Anthropic 的 API。
在会话中,输入命令 /model 以确认连接的是哪个模型。从这里开始的每次回复都不需要代币。
专业提示:在第二个终端中 运行命令 ollama ps ,即可查看实际运行的程序。它会显示当前运行的模型、内存使用情况和 GPU 利用率。100% 的 GPU 利用率表示程序已完全加速。低于此值则表示部分模型运算转移到了 CPU,响应速度会变慢。
第四步:在进行任何重要操作之前,请先关闭上下文窗口。
这是整个设置中最重要的一项。默认情况下,Ollama 为每个模型仅分配 4K 的上下文空间 ,这对于智能体编程来说远远不够。Claude Code 会读取一个文件,填满缓冲区,然后立即开始遗忘对话的其余部分。
一次解决,以后就不用再操心了:
打开 Ollama 应用
Ollama菜单 > 设置
找到 “上下文” 滑块
先把频率调到 32K ,如果你的电脑配置允许,可以调得更高。
专业提示: 询问您的 LLM(LLM,LLM 管理员)您的配置可以安全处理的最大上下文大小。将上下文大小设置为最大值可能会超出 GPU 的极限,导致程序崩溃。建议从 32K 开始,使用 `catch` 命令验证 ollama ps,如果还有余力,再逐步增加。
第五步:如果觉得 Claude Code 太臃肿,可以试试 OpenCode。
Claude Code 是一个功能强大的工具集,一次性提供了大量工具。小型本地模型有时会因选择过多而感到困惑。OpenCode 是 一个轻量级的编码代理,专为这种情况而设计,它采用了相同的 ollama launch 模式。
只需一行命令即可在 Mac 上安装:
curl -fsSL https://opencode.ai/install | bash
然后以同样的方式启动它:
ollama launch opencode --modelgemma4:e4b
专业提示: 较小的模型在减少思考量时效果更好。在 Claude Code 或 OpenCode 中按 Shift+Tab 可切换计划模式(智能体会在处理文件之前先编写其方案)。如果智能体对简单的任务过度思考,请在设置中降低推理难度。
更进一步
一旦基础架构运行正常,最具杠杆效应的策略就是采用 混合架构。继续付费使用 Claude Code 或 Codex 作为主代理,但将本地模型配置为由其协调的低成本子代理。前沿模型负责架构和规划,本地模型则负责处理繁琐的样板工作。这样,您可以保留智能工作,并将低成本工作外包出去,从而大幅降低代币消耗。
还有两个地方可以去:
通过手机远程控制本地会话。 进入 claude remote-control 会话后,使用 Claude 移动应用扫描二维码。您可以在办公桌前启动任务,然后随时随地进行监控。
将模型放在一台专用机器上。 一台旧的 Mac mini 或一台改装过的 PC 都是很棒的常开本地推理服务器。通过网络从你的笔记本电脑访问它,就不用再跟你的主力机争夺内存了。
本地模型目前还不能完全替代前沿的云端编码代理。可以将其视为练习环境、敏感项目的隐私保护层,以及无需前沿推理任务的预算对冲方案。这种差距每隔几个月就会缩小。
评论
0 条登录后才可以发表评论。
立即登录